本文共 2986 字,大约阅读时间需要 9 分钟。
Azure Databricks 是基于 Apache Spark 的分析平台,已针对 Microsoft Azure 云服务平台进行优化。微软与 Apache Spark 的创建者一起设计了 Databricks,并将其与 Azure 集成以提供一键式安装、简化的工作流程以及交互式工作区,从而使数据科学家、数据工程师和业务分析员可以紧密合作。2020年10月1日,微软超高性能企业级Spark大数据分析服务 Azure Databricks,在由世纪互联运营的Microsoft Azure 上正式推出公开预览版。
什么是Azure Databricks
Azure Databricks 是基于Apache Spark 的快速、简单、协作型分析服务。使用大数据管道时,原始或结构化的数据将通过 Azure 数据工厂以批的形式引入 Azure,或者通过 Kafka、事件中心、 IoT 中心进行准实时的流式传输。此数据将驻留在 Data Lake(长久存储)、Azure Blob 存储或 Azure Data Lake Storage 中。在运行分析工作流的过程中,用户可以使用 Azure Databricks 从 Azure Blob 存储、Azure Data Lake Storage、Azure Cosmos DB 或 Azure SQL 数据仓库等多个数据源读取数据,并使用 Spark 将数据转化为前所未有的见解。
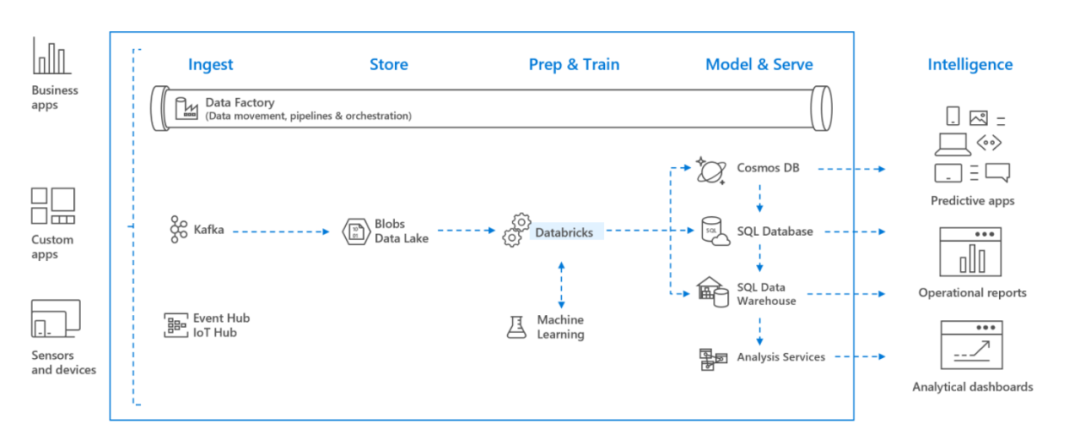
基于 Apache Spark 的分析平台
Azure Databricks 包含完整的开源 Apache Spark 群集技术和功能。Azure Databricks 中的 Spark 包括以下组件:
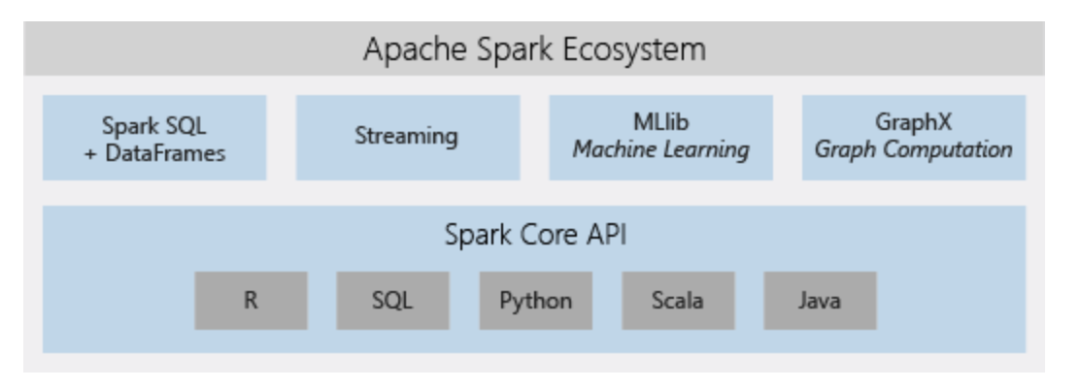
- Spark SQL 和数据帧:Spark SQL 是用于处理结构化数据的 Spark 模块。数据帧是已组织成命名列的分布式数据集合。 它在概念上相当于关系型数据库中的表,或 R/Python中的数据帧。
-
流式处理:实时数据处理和分析,适用于分析与交互式应用程序。与HDFS、Flume 和 Kafka 集成。
-
MLlib:由常见学习算法和实用工具(包括分类、回归、群集、协作筛选、维数约简以及底层优化基元)组成的机器学习库。
-
GraphX:图形和图形计算,适用于从认知分析到数据探索的广泛用例。
-
Spark Core API:包含对 R、SQL、Python、Scala 和 Java 的支持。
Azure Databricks 中的 Apache Spark
Azure Databricks 构建在 Spark 功能基础之上,提供一个无管理云平台,其中包括:
-
完全托管的 Spark 群集。
-
可浏览和可视化数据的交互式工作区。
-
为喜爱的基于 Spark 的应用程序提供支持的平台。
在云中完全托管的 Apache Spark 群集
Azure Databricks 在云中拥有安全可靠的生产环境,由 Spark 专家进行管理和提供支持。 可以:
-
在几秒钟内创建群集。
-
动态自动扩展和缩减群集(包括无服务器群集)并在团队中共享群集。
-
通过 REST API 以编程方式使用群集。
-
使用基于 Spark 的安全数据集成功能,在无需集中化的情况下统一数据。
-
即时获得每个版本中的最新 Apache Spark 功能。
Databricks 运行时
Databricks 运行时构建在 Apache Spark 的基础之上,并且是对 Azure 云原生构建的。
与“无服务器”选项一样,Azure Databricks 完全消除了设置和配置数据基础结构所存在的基础结构复杂性以及所需的专业知识。 “无服务器”选项可帮助数据科学家以团队形式快速迭代。
对于关注生产作业性能的数据工程师而言,Azure Databricks 通过 I/O 层和处理层 (Databricks I/O) 的各种优化提供了一个更快速、更高效的 Spark 引擎。
实现协作的工作区
通过协作和集成式环境,Azure Databricks 简化了在 Spark 中浏览数据、制作原型和运行数据驱动型应用程序的过程。
-
通过简单的数据浏览确定如何使用数据。
-
在以 R、Python、Scala 或 SQL 编写的笔记本中记录进度。
-
几步内即可实现数据可视化,可使用熟悉的工具,例如 Matplotlib、ggplot 或 d3。
-
使用交互式仪表板创建动态报告。
-
在使用 Spark 的同时与数据交互。
企业安全性
Azure Databricks 提供企业级的 Azure 安全性,包括 Azure Active Directory 集成、基于角色的控制,以及可保护数据和业务的 SLA。
-
与Azure Active Directory 集成后,可以使用 Azure Databricks 运行基于 Azure 的完整解决方案。
-
Azure Databricks 基于角色的访问可以细化用户对笔记本、群集、作业和数据的权限。
-
企业级 SLA。
Azure Databricks 解决方案结构
轻松从实时流数据中获取见解。持续从所有 IoT 设备或网站点击流日志捕获数据,并实时地处理数据。
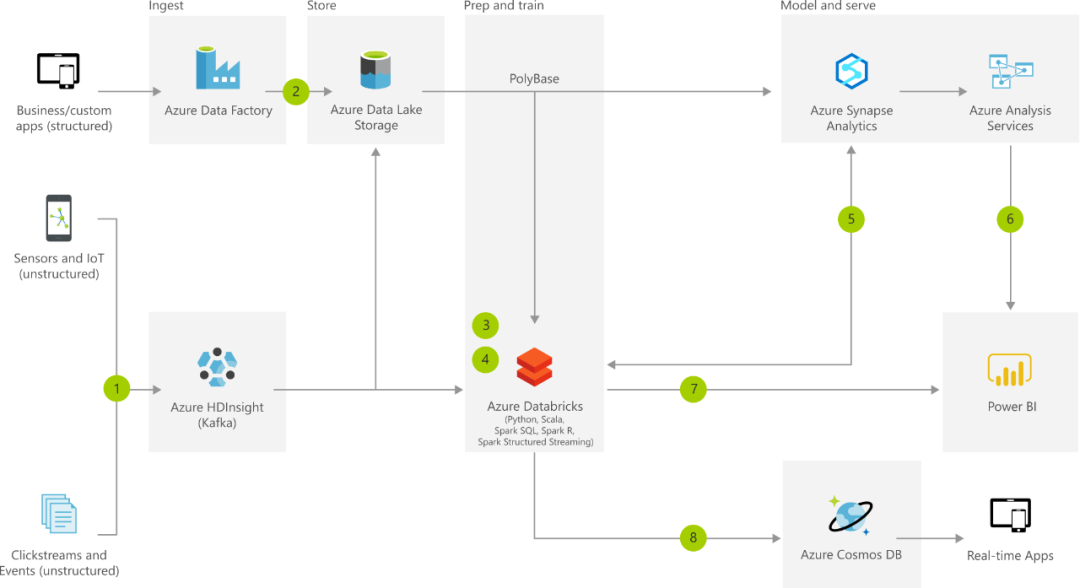
使用领先机器学习工具将数据转化为可行见解。通过这种架构,可将任何规模的数据进行组合,且可大规模构建和部署自定义机器学习模型。
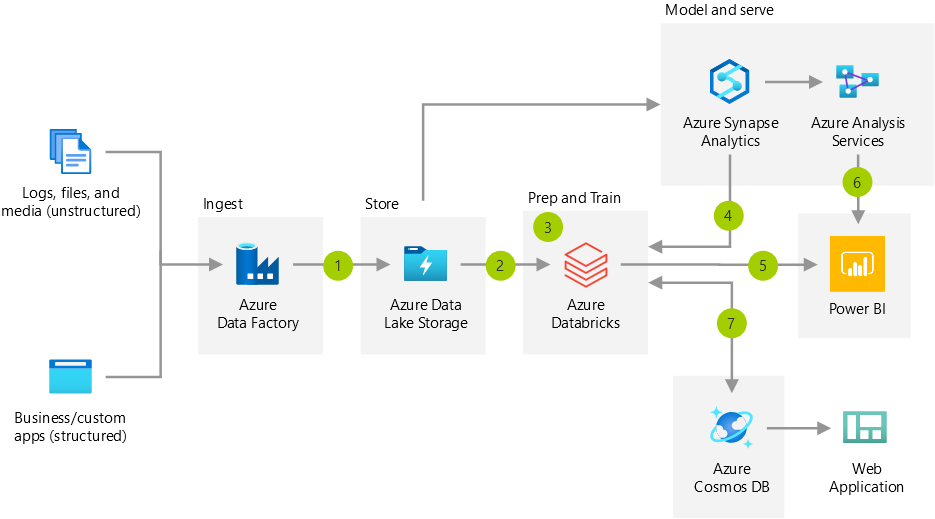
利用 Azure Databricks、MLflow 和 Azure 机器学习加速和管理端到端机器学习生命周期,以生成、共享、部署和管理机器学习应用程序。
为什么选择Azure Databricks
开源版本不具备的功能
-
Databricks 工作区:交互式数据科学与协作。
-
Databricks 工作流:生产任务和工作流程自动化。
-
Databricks Runtime。
-
Databricks I/O (DBIO):优化的数据访问层。
-
Databricks 无服务器:完全托管的自动调优平台。
-
Databricks 企业安全 (DBES):端到端的安全性与合规性。
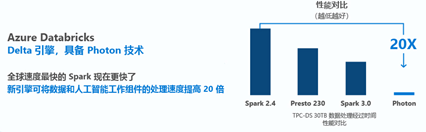
加强生产力
-
快速启用:只需点击一下,即可启动新的 Spark 环境。
-
与 Power BI 的丰富集成能帮助您十分有效地分享见解。
-
利用统一的工作区帮助分析团队改善彼此之间协作。
-
与其余 Azure 平台产品服务的原生集成,加快创新速度。
基于最合规的云平台而构建
-
与 Active Directory 的内置集成可简化安全性和身份控制。
-
使用颗粒级用户权限实现对 Azure Databricks 的笔记本、集群、作业和数据的访问控制。
-
提供强大的技术支持、合规性和 SLA,在可信云平台上放心构建。
无限可扩展
-
可在全球范围内不受技术限制地进行大规模运营。
-
使用目前最快的Spark 引擎加快数据处理速度。

Azure Databricks 主要受众和优势
快速入门
如果您想要借助微软超高性能Spark 大数据分析服务,加快数据驱动的企业创新,请参考以下步骤,即刻开启Azure Databricks 体验之旅。
1. 注册 , 获得即时访问权限
2. 参阅 , 了解如何使用 Azure Databricks
3. 浏览 ,即刻在Databricks 中创建Spark 群集
转载地址:http://yjrtf.baihongyu.com/